This is the webpage for our ICLR 2019 project. Below, you can find a brief technical description of the method, and the video results. Make sure to also check out our paper and/or the poster by the links above.
Model
Action-conditioned video prediction models that use a given robot action to predict it’s consequences have received considerable attention for their promising applications to planning and real-world robotic control (Oh et al. 2015, Finn & Levine 2017, Byravan et al. 2017). In this work, we extend this line of research to learning from passive observations, i.e. observations that don’t contain the actions that produced them. We want to learn an action space of a robot, as well as a predictive model of observations given actions.
The base model we use is a recurrent conditional variational autoencoder (Chung et al., 2015; Denton & Fergus, 2018; Lee et al., 2018) that has a recurrent latent variable z:
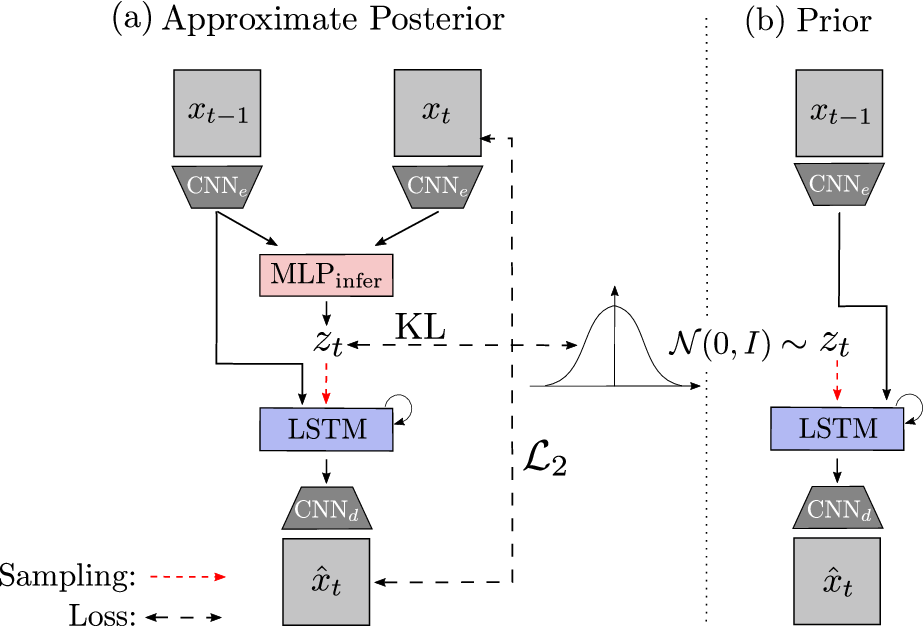
We extend this work and introduce a novel objective that encourages z to represent the actions of the robot. The first necessary requirement is that z contains the same amount of information as the variable that corresponds to the true actions u. To enforce this, we introduce the assumption that the only source of stochasticity in our visual observations are the robot actions, in other words, the environment dynamics are deterministic (lifting this assumption is left to future work). With this assumption, the information equivalence requirement will be satisfied if the variable z is a minimal representation of the stochasticity of the environment. The information minimality can be enforced by modifying the VAE objective in the model above to the Variational Information Bottleneck objective (VIB, Alemi et al., 2017; same as β-VAE objective, Higgins et al, 2017).
However, the minimality is not enough to enforce that the variable z has consistent meaning across different robot states (see also Fig. 12 of the Appendix):
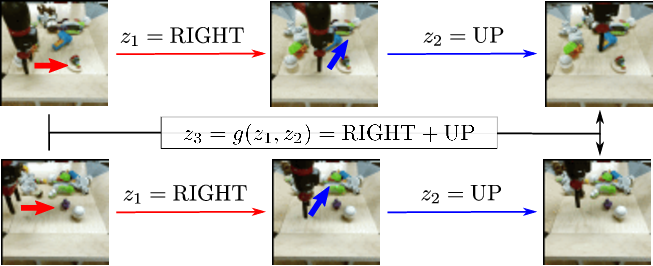
To learn a representation disentangled from the static state and the visual characteristics, we introduce a composability objective:
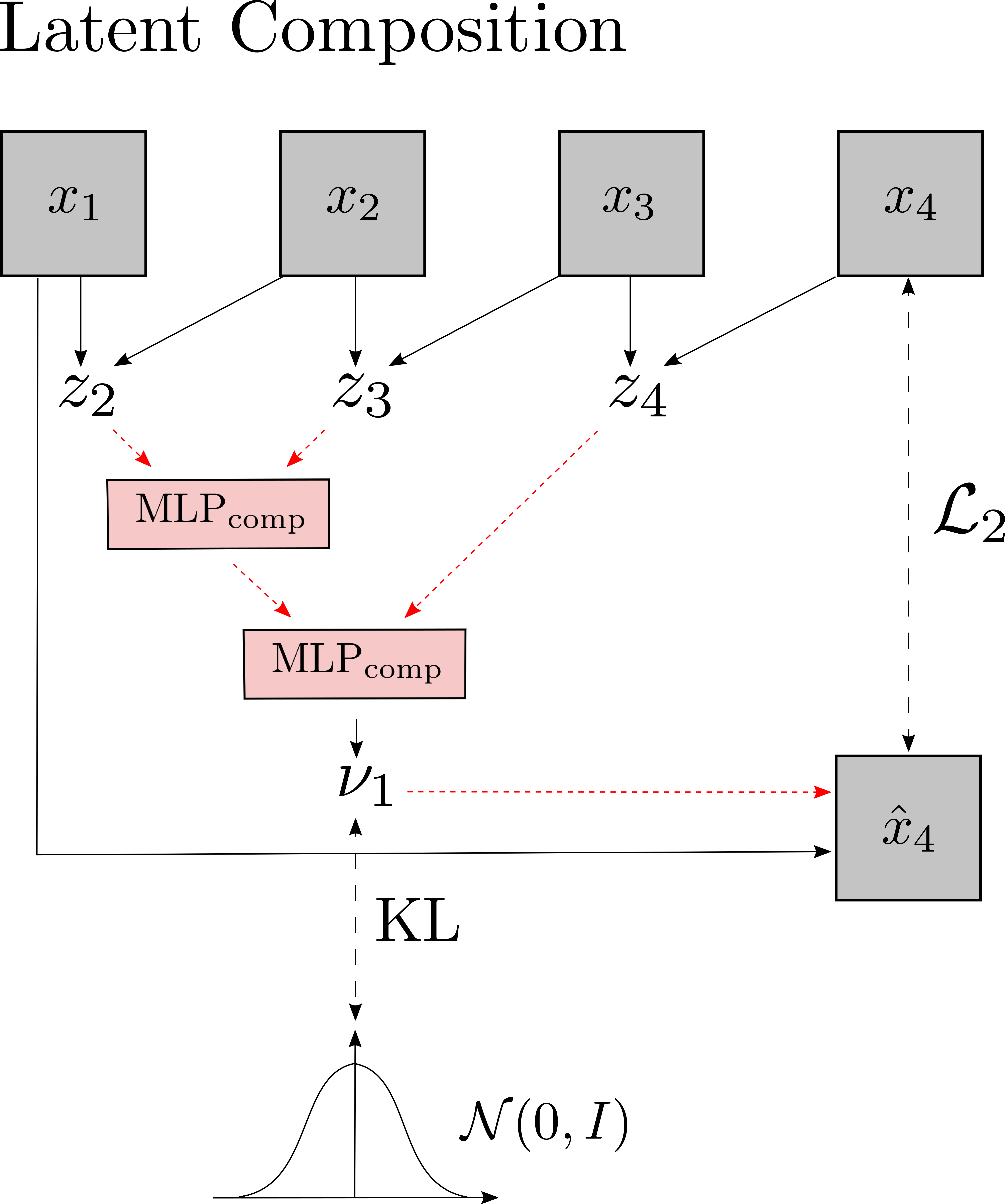
We enforce that ν has a minimal representation by using VIB. Experimentally, we confirm that minimality together with composability are enough to learn a disentangled representation in the experimental evaluation below.
Experiments
Our model, if a disentangled representation is learned, can be used the same way as action-conditioned models, but requires far less videos labeled with robot actions. We show that the model can be successfully used for action-conditioned prediction and planning (much like Finn et al., 2017) on a synthetic dataset and shows promise on a real-world BAIR dataset. The baseline consistently fails to perform both tasks.
Below, we show representative example videos predicted by our model.
BAIR pushing dataset results
We see that while our model doesn’t perfectly model the robot motion, the frequency of artifacts present in the baseline is much lower. In the videos predicted by baseline, there is a strong presence of artifacts, such as the robot arm disappearing and appearing in another location, or two arms present in the video.




BAIR - baseline failure cases


Reacher results


Reacher with varied backgrounds


Reacher with varied agent appearance


Discussion
Passive unsupervised learning from observing agents acting in an environment provides a viable alternative to active model-based techniques when abundant action-labeled data is not available, such as when collecting data from the Internet. We show that our approach is able to learn a meaningful representation of the robot’s actions, and is useful for planning on a servoing task, while requiring much less active supervision than prior work.
BibTeX
@inproceedings{
rybkin2019learning,
title={Learning what you can do before doing anything},
author={Oleh Rybkin* and Karl Pertsch* and Konstantinos G. Derpanis and Kostas Daniilidis and Andrew Jaegle},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=SylPMnR9Ym},
}